AidGenSE RAG 服务部署指南
介绍
RAG (Retrieval-Augmented Generation,检索增强生成) 是一种结合了信息检索和文本生成的技术架构,广泛应用于问答系统、企业搜索、文档助手等生成式AI场景中。它的基本思想是在生成答案前先从外部知识源中检索相关信息,从而提升回答的准确性和可控性。
AidGenSE 内置了 RAG 相关组件,方便开发者快速部署自己的 RAG 应用。
支持情况
目前内置了两个 Demo 知识库
| 知识库名称 | 使用 Embedding Model |
|---|---|
| 特斯拉使用手册 | BAII/bge-large-zh-v1.5 |
| 汽车维修手册 | BAII/bge-large-zh-v1.5 |
快速开始
安装
安装 AidGenSE 相关组件,请参考 AidGenSE 安装
安装 RAG 组件
bash
# 安装 RAG 服务
sudo aid-pkg update
sudo aidllm install rag查看可用向量知识库
bash
aidllm remote-list rag示例输出:
bash
Name EmbeddingModel CreateTime
---- ---------------------------- --------------------
tesla BAII/bge-large-zh-v1.5 2025-04-14 09:59:43
mechanical BAII/bge-large-zh-v1.5 2025-04-14 09:59:43下载指定知识库
bash
# 下载指定知识库
aidllm pull rag [rag_name] # e.g: tesla
# 查看已下载的知识库
aidllm list rag
# 删除已下载的知识库
sudo aidllm rm rag [rag_name] # e.g: tesla启动服务
bash
# 指定模型启动
aidllm start api -m <model_name>
# 启动指定知识库
aidllm start rag -n <rag_name>对话测试
使用 Web UI 对话测试
bash
# 安装 UI 前端服务
sudo aidllm install ui
# 启动 UI 服务
aidllm start ui
# 查看 UI 服务状态
aidllm status ui
# 停止 UI 服务
aidllm stop ui💡注意
UI 服务启动后访问 http://ip:51104
使用 Python 对话测试
python
import os
import requests
import json
RAG_PROMPT = '''
你是一名智能助手。你的目标是提供准确的信息,并尽可能帮助提问者解决问题。你应保持友善,但不要过于啰嗦。请根据提供的上下文信息,在不考虑已有知识的情况下,回答相关查询。如果没有提供上下文信息,请根据你所了解到的知识,回答相关查询。
上下文内容:
{response}
提取"{question}"涉及到的问题并回答。
'''
def rag_query(question):
url = "http://127.0.0.1:18111/query"
# 设置 RAG 知识库
rag_name = "<rag_name>"
headers = {
"Content-Type": "application/json"
}
payload = {
"text": question,
"collection_name": rag_name,
"top_k": 1,
"score_threshold": 0.1
}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
result = response.json()
answer = ""
if len(result['data']) > 0:
answer = result['data'][0]['text']
return RAG_PROMPT.format(response=answer, question=question)
return question
def stream_chat_completion(messages, model="<model_name>"): # 设置大模型
url = "http://127.0.0.1:8888/v1/chat/completions"
headers = {
"Content-Type": "application/json"
}
payload = {
"model": model,
"messages": messages,
"stream": True # 打开流式
}
# 发起带 stream=True 的请求
response = requests.post(url, headers=headers, json=payload, stream=True)
response.raise_for_status()
# 逐行读取并解析 SSE 格式
for line in response.iter_lines():
if not line:
continue
# print(line)
line_data = line.decode('utf-8')
# SSE 每一行以 "data: " 前缀开头
if line_data.startswith("data: "):
data = line_data[len("data: "):]
# 结束标志
if data.strip() == "[DONE]":
break
try:
chunk = json.loads(data)
except json.JSONDecodeError:
# 解析出错时打印并跳过
print("无法解析JSON:", data)
continue
# 取出模型输出的 token
content = chunk["choices"][0]["delta"].get("content")
if content:
print(content, end="", flush=True)
if __name__ == "__main__":
# 设置问题
user_input = "<question>"
rag_query = rag_query(user_input)
print("user input:", user_input)
print("rag query:", rag_query)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": rag_query}
]
print("Assistant:", end=" ")
stream_chat_completion(messages)
print() # 换行示例:在高通 8550 上使用 Qwen2.5-3B-Instruct 和车载手册知识库
- 安装 AidGenSE 和 RAG 组件
bash
# 安装 aidgense
sudo aid-pkg -i aidgense
# 安装 RAG 服务
sudo aidllm install rag- 下载
Qwen2.5-3B-Instruct模型和车载手册知识库
bash
# 下载模型
aidllm pull api aplux/qwen2.5-3B-Instruct-8550
# 下载车载手册知识库
aidllm pull rag tesla- 启动服务
bash
# 指定模型启动
aidllm start api -m qwen2.5-3B-Instruct-8550
# 启动指定知识库
aidllm start rag -n tesla- 使用 Web UI 对话测试
bash
# 安装 UI 前端服务
sudo aidllm install ui
# 启动 UI 服务
aidllm start ui- 使用 Python 对话测试
python
import os
import requests
import json
RAG_PROMPT = '''
你是一名智能助手。你的目标是提供准确的信息,并尽可能帮助提问者解决问题。你应保持友善,但不要过于啰嗦。请根据提供的上下文信息,在不考虑已有知识的情况下,回答相关查询。如果没有提供上下文信息,请根据你所了解到的知识,回答相关查询。
上下文内容:
{response}
提取"{question}"涉及到的问题并回答。
'''
def rag_query(question):
url = "http://127.0.0.1:18111/query"
# 设置 RAG 知识库
rag_name = "tesla"
headers = {
"Content-Type": "application/json"
}
payload = {
"text": question,
"collection_name": rag_name,
"top_k": 1,
"score_threshold": 0.1
}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
result = response.json()
answer = ""
if len(result['data']) > 0:
answer = result['data'][0]['text']
return RAG_PROMPT.format(response=answer, question=question)
return question
def stream_chat_completion(messages, model="qwen2.5-3B-Instruct-8550"): # 设置大模型
url = "http://127.0.0.1:8888/v1/chat/completions"
headers = {
"Content-Type": "application/json"
}
payload = {
"model": model,
"messages": messages,
"stream": True # 打开流式
}
# 发起带 stream=True 的请求
response = requests.post(url, headers=headers, json=payload, stream=True)
response.raise_for_status()
# 逐行读取并解析 SSE 格式
for line in response.iter_lines():
if not line:
continue
# print(line)
line_data = line.decode('utf-8')
# SSE 每一行以 "data: " 前缀开头
if line_data.startswith("data: "):
data = line_data[len("data: "):]
# 结束标志
if data.strip() == "[DONE]":
break
try:
chunk = json.loads(data)
except json.JSONDecodeError:
# 解析出错时打印并跳过
print("无法解析JSON:", data)
continue
# 取出模型输出的 token
content = chunk["choices"][0]["delta"].get("content")
if content:
print(content, end="", flush=True)
if __name__ == "__main__":
# 设置问题
user_input = "车钥匙丢了怎么办"
rag_query = rag_query(user_input)
print("user input:", user_input)
print("rag query:", rag_query)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": rag_query}
]
print("Assistant:", end=" ")
stream_chat_completion(messages)
print() # 换行创建自定义 RAG 知识库
一、准备工作
注册账号
访问 aidlux 官网,注册并登录一个 Aidlux 账号。登录 aidllm-cms
打开浏览器访问 https://aidllm.aidlux.com,使用你的 Aidlux 账号登录。
二、创建 RAG 知识库
进入知识库管理界面
登录后点击左侧“知识库”菜单,进入管理页面,点击“新建”。
填写知识库信息
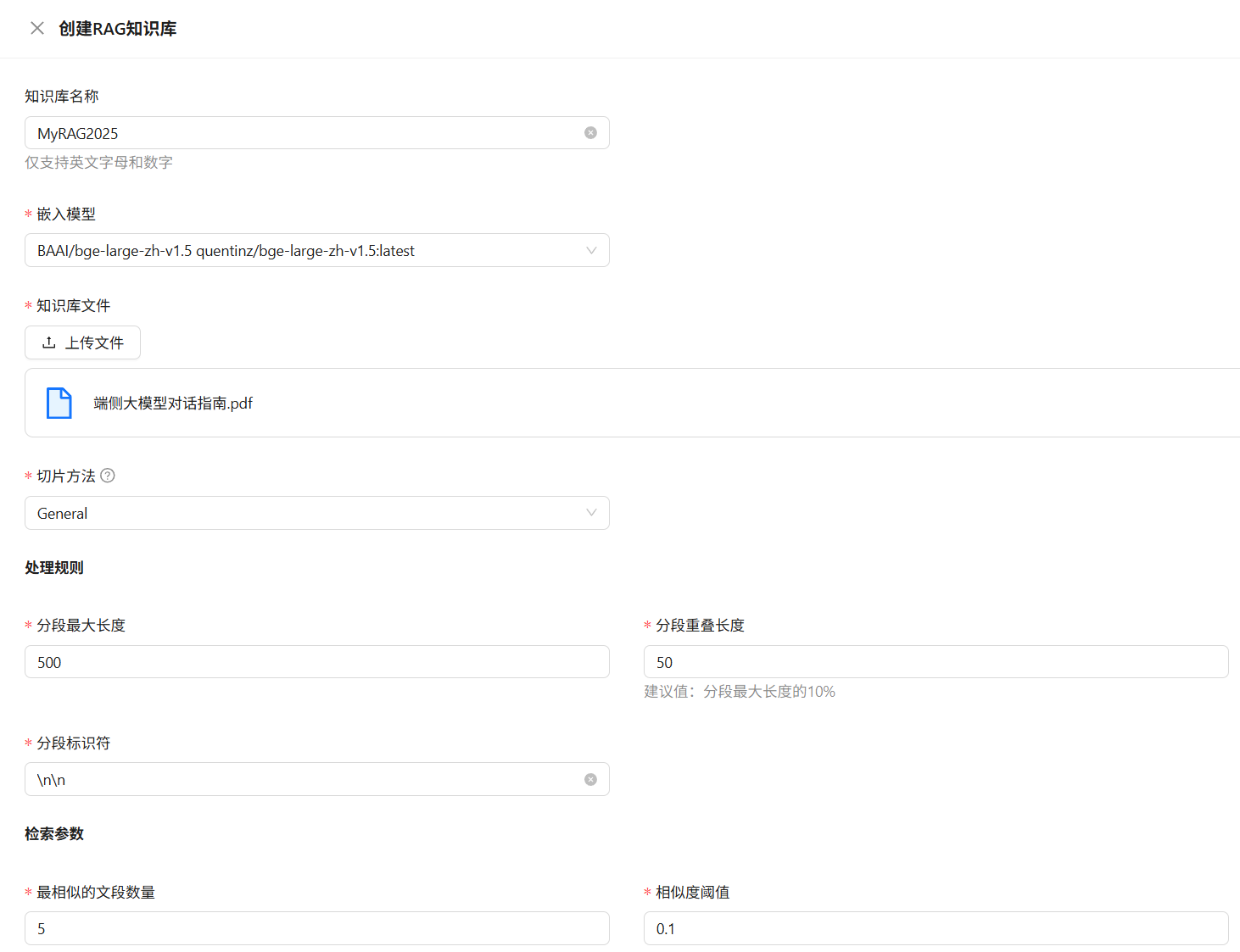
名称:仅支持英文字母和数字(如:
MyRAG2025)。嵌入模型:选择当前已加载的 embedding 模型。
切片方法:可选
General或Q&A,具体说明如下:切片方法 支持格式 说明 General文本(.txt / .pdf) 将连续文本按“分段标识符”分割,再按 Token 数量不超过“最大长度”合并为一块。 Q&A.xlsx / .csv / .txt 用于问答格式:Excel 两列(无表头:问题 / 答案);CSV / TXT 使用 Tab 分隔,UTF-8 编码。
注意事项
- 创建的知识库默认仅对自己可见。
- 使用命令行工具时,仅可查看公开知识库及自己创建的私有知识库。
三、知识库服务启动
登录远程 cms
bashaidllm login使用注册的 Aidlux 账号进行登录。
该操作仅用于执行远程知识库相关命令。查看知识库列表
bashaidllm remote-list rag Name EmbeddingModel CreateTime aidluxdocs BAAI/bge-large-zh-v1.5 2025-07-09 14:56:31 MyRAG2025 BAAI/bge-large-zh-v1.5 2025-07-21 16:08:14拉取知识库
bashaidllm pull rag <知识库名称> aidllm pull rag MyRAG2025启动 RAG 服务
bashaidllm start rag -n <rag_name> Use rag: MyRAG2025 Use model: bge-large-zh-v1.5 Rag server starting... Rag server starting... Rag server starting... Rag server starting... Rag server starting... Rag server starting... Rag server start successfully.成功后本地将开启知识检索服务。