AidLite SDK
Introduction
AidLite SDK is an AI execution framework developed by APLUX, designed to fully utilize the computing units (CPU, GPU, NPU) of edge devices to achieve accelerated AI model inference.
AidLite provides the unified AI inference development across platforms. It abstracts calls to different AI inference frameworks into a unified API, allowing for decoupled and flexible model inference development.
The features are illustrated below:
AidLite's highly unified API abstraction supports different AI frameworks, allowing developers to build once and deploy across different chips and frameworks. This greatly reduces learning costs and platform migration difficulties, enabling flexible technical choices and faster product deployment.
Other features:
- Supports mainstream AI chipmaker specific AI accelerator (NPU), eg: Qualcomm NPU, Rockchip NPU
- Supports fetching model properties, eg: model input share, output shape
- Supports APLUX Model Format (*.amf)
- Supports Shared-Buffer between CPU and NPU, which reduced the inference time
Supported Matrix
Operating System Support
| Linux | Android | |
|---|---|---|
| C++ | ✅ | / |
| Python | ✅ | / |
| Java | / | ✅ |
Supported AI Inference Framework
| Qualcomm SNPE | Qualcomm QNN | Rockchip RKNN | TFLite | ONNX | Paddle-Lite | MNN | MindSpore | |
|---|---|---|---|---|---|---|---|---|
| AidLite for Linux | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| AidLite for Android | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
✅: Supported
🚧: Planing
Quick Start
AidLite integrates multiple deep learning inference frameworks at the backend, so the inference process and required APIs remain highly consistent regardless of the model framework.
💡Note
If you are using a development board provided by APLUX, the development Kit are pre-installed and activation has be completed, so developers can skip Installation step.
Installation
sudo aid-pkg update
sudo aid-pkg install aidlite-sdk
# Install the latest version of AidLite (latest QNN version)
sudo aid-pkg install aidliteTo be released💡Note
In Linux, to install AidLite SDK with a specific QNN version: sudo aid-pkg install aidlite-{QNN Version}
Example: To install AidLite SDK with QNN 2.16 — sudo aid-pkg install aidlite-qnn216
- Validation AidLite Installation
# aidlite sdk c++ check
python3 -c "import aidlite; print(aidlite.get_library_version())"
# aidlite sdk python check
python3 -c "import aidlite; print(aidlite.get_py_library_version())"To be releasedAPI Documentation
- AidLite for Linux Python API Documentation
- AidLite for Linux C++ API Documentation
- AidLite for Android Java API Documentation
Development Flowchart
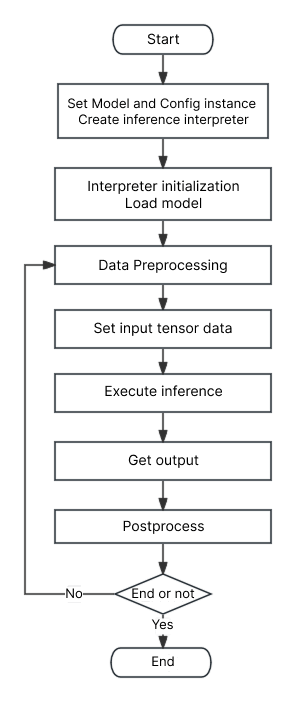
Development Workflow Explanation
💡Note
The following code demonstrates the core development flow. For full API details, refer to the AidLite API Documentation.
The following points should be noted when developing with AidLite SDK in C++:
- During compilation, you need to include the header file located at
/usr/local/include/aidlux/aidlite/aidlite.hpp. - During linking, you need to specify the library file located at
/usr/local/lib/libaidlite.so.
# Print SDK version and configure logging
print(f"Aidlite library version : {aidlite.get_library_version()}")
print(f"Aidlite Python library version : {aidlite.get_py_library_version()}")
# aidlite.set_log_level(aidlite.LogLevel.INFO)
# aidlite.log_to_stderr()
# aidlite.log_to_file("./fast_SNPE_inceptionv3_")
# Create a Model instance and set model parameters
model = aidlite.Model.create_instance(model_path)
if model is None:
print("Create model failed !")
return False
input_shapes = [[1,320,320,3]]
output_shapes = [[1,10,10,255],[1,20,20,255],[1,40,40,255]]
model.set_model_properties(input_shapes, aidlite.DataType.TYPE_FLOAT32, output_shapes, aidlite.DataType.TYPE_FLOAT32)
# Create a Config instance and set configuration
config = aidlite.Config.create_instance()
if config is None:
print("build_interpreter_from_model_and_config failed !")
return False
config.framework_type = aidlite.FrameworkType.TYPE_SNPE
config.accelerate_type = aidlite.AccelerateType.TYPE_DSP
config.is_quantify_model = 1
config.snpe_out_names = ["InceptionV3/Predictions/Softmax"]
# Build the inference interpreter
fast_interpreter = aidlite.InterpreterBuilder.build_interpreter_from_model_and_config(model, config)
if fast_interpreter is None:
print("build_interpreter_from_model_and_config failed !")
return None
# Initialize the interpreter
result = fast_interpreter.init()
if result != 0:
print(f"interpreter init failed !")
return False
# Load the model
result = fast_interpreter.load_model()
if result != 0:
print("interpreter load model failed !")
return False
# Complete inference process typically involves: Preprocessing + Inference + Postprocessing
# Preprocessing varies by model
input_tensor_data = preprocess()
# Set the input tensor data for inference
result = fast_interpreter.set_input_tensor(0, input_tensor_data)
if result != 0:
print("interpreter set_input_tensor() failed")
return False
# Run inference
result = fast_interpreter.invoke()
if result != 0:
print("interpreter set_input_tensor() failed")
return False
# Retrieve output tensor data
out_data = fast_interpreter.get_output_tensor(0)
if out_data is None:
print("sample : interpreter->get_output_tensor() 0 failed !")
return False
# Postprocessing varies by model
result = postprocess(out_data)
# Release interpreter resources
result = fast_interpreter.destroy()
if result != 0:
print("interpreter destroy() failed !")
return False// Get SDK version info and configure logging
printf("Aidlite library version : %s\n", Aidlux::Aidlite::get_library_version().c_str());
// Aidlux::Aidlite::set_log_level(Aidlux::Aidlite::LogLevel::INFO);
// Aidlux::Aidlite::log_to_stderr();
// Aidlux::Aidlite::log_to_file("./fast_snpe_inceptionv3_");
// Create a Model instance and set model properties
Model* model = Model::create_instance("./inceptionv3_float32.dlc");
if(model == nullptr){
printf("Create model failed !\n");
return EXIT_FAILURE;
}
std::vector<std::vector<uint32_t>> input_shapes = {{1,299,299,3}};
std::vector<std::vector<uint32_t>> output_shapes = {{1,1001}};
model->set_model_properties(input_shapes, DataType::TYPE_FLOAT32,
output_shapes, DataType::TYPE_FLOAT32);
// Create a Config instance and set configuration
Config* config = Config::create_instance();
if(config == nullptr){
printf("Create config failed !\n");
return EXIT_FAILURE;
}
config->framework_type = FrameworkType::TYPE_SNPE;
config->accelerate_type = AccelerateType::TYPE_CPU;
// config->is_quantify_model = 0;
config->snpe_out_names.push_back("InceptionV3/Predictions/Softmax");
// Build the inference interpreter
std::unique_ptr<Interpreter>&& fast_interpreter =
InterpreterBuilder::build_interpreter_from_model_and_config(model, config);
if(fast_interpreter == nullptr){
printf("build_interpreter_from_model_and_config failed !\n");
return EXIT_FAILURE;
}
// Initialize the interpreter
int result = fast_interpreter->init();
if(result != EXIT_SUCCESS){
printf("sample : interpreter->init() failed !\n");
return EXIT_FAILURE;
}
// Load the model
fast_interpreter->load_model();
if(result != EXIT_SUCCESS){
printf("sample : interpreter->load_model() failed !\n");
return EXIT_FAILURE;
}
// Inference workflow typically includes: Preprocessing + Inference + Postprocessing
{
// Preprocessing varies by model
void* input_tensor_data = preprocess();
// Set input tensor data
result = fast_interpreter->set_input_tensor(0,input_tensor_data);
if(result != EXIT_SUCCESS){
printf("sample : interpreter->set_input_tensor() failed !\n");
return EXIT_FAILURE;
}
// Run inference
result = fast_interpreter->invoke();
if(result != EXIT_SUCCESS){
printf("sample : interpreter->invoke() failed !\n");
return EXIT_FAILURE;
}
// Get output tensor data
float* out_data = nullptr;
uint32_t output_tensor_length = 0;
result = fast_interpreter->get_output_tensor(0, (void**)&out_data, &output_tensor_length);
if(result != EXIT_SUCCESS){
printf("sample : interpreter->get_output_tensor() failed !\n");
return EXIT_FAILURE;
}
// Postprocessing varies by model
int32_t result = postprocess(out_data);
}
// Release interpreter resources
result = fast_interpreter->destroy();
if(result != EXIT_SUCCESS){
printf("interpreter->destroy() failed !\n");
return EXIT_FAILURE;
}To be releasedExample
💡Note
Developers can access Model Farm to download more model examples (including pre-processing and post-processing).
For the usage documentation of Model Farm, please refer to: Model Farm User Guide
Using AidLite (QNN2.31) to Run YOLOv5 Inference on Qualcomm NPU
AidLite provides a YOLOv5 example in the Linux environment, located at /uer/local/share/aidlite/examples/. The step to run example showed below:
mkdir -p /home/aidlux/aidlite_demo/
cp -r /uer/local/share/aidlite/examples/ /home/aidlux/aidlite_demo/
cd /home/aidlux/aidlite_demo/aidlite_qnn231/python
python qnn_yolov5_multi.py
sudo apt update
sudo apt-get install cmake -y
mkdir -p /home/aidlux/aidlite_demo/
cp -r /uer/local/share/aidlite/examples/ /home/aidlux/aidlite_demo/
cd /home/aidlux/aidlite_demo/aidlite_qnn231/cpp
mkdir -p build && cd build
cmake ..
make
/xxx.exeTo be released